elementui
ssm
DEFI
驱动程序
业务大屏
armv9
电路
美食论坛系统
线性表
salesforce
coinbase
质量管理
引用类型
gunicorn
DDD
matlab入门教程
reference手册
k8s
天线
倍福
豆瓣
2024/4/26 14:21:19
Python自定义豆瓣电影种类,排行,点评的爬取与存储(初级)
Python 2.7 IDE Pycharm 5.0.3 Firefox 47.0.1
具体Selenium和PhantomJS配置及使用请看调用PhantomJS.exe自动续借图书馆书籍 网上一溜豆瓣TOP250---有意思么?起因
就是想写个豆瓣电影的爬取,给我电影荒的同学。。。。当然自己也练手啦 目的
1.根据…
豆瓣电影分析报告:大陆和港台到底差(cha)在哪里?
Python 2.7 IDE Pycharm 5.0.3 PyExcelerator 0.6.4a 可视化 Plotly 图片要是挂了
请看这里此文备份链接 前言 在上次爬完豆瓣的东西后,感觉锻(zhuang)炼(yi)能(xia)力(bi)之外,貌似并没有实际用处,说实话,我宁可去网页一页页…

电影产业的数据洞察:爬虫技术在票房分析中的应用
概述
电影产业是一个庞大而复杂的行业,涉及到各种各样的因素,如导演、演员、类型、主题、预算、宣传、口碑、评分、奖项等。这些因素都会影响电影的票房收入,也会反映出电影市场的动态和趋势。为了更好地了解电影产业的数据洞察,…

从零开始制作一个Douban图像下载器:Wt库的基础知识和操作指南
引言
欢迎来到本文,如果你希望从豆瓣下载海量的高清图像、学习使用现代C web应用程序框架Wt库开发web应用程序,或者了解如何利用代理IP和多线程技术提高爬虫效率和稳定性,那么你来对地方了。在接下来的内容中,我们将为你提供一个…

深入浅出:Objective-C中使用MWFeedParser下载豆瓣RSS
摘要
本文旨在介绍如何在Objective-C中使用MWFeedParser库下载豆瓣RSS内容,同时展示如何通过爬虫代理IP技术和多线程提高爬虫的效率和安全性。
背景
随着信息量的激增,爬虫技术成为了获取和处理大量网络数据的重要手段。Objective-C作为一种成熟的编程…
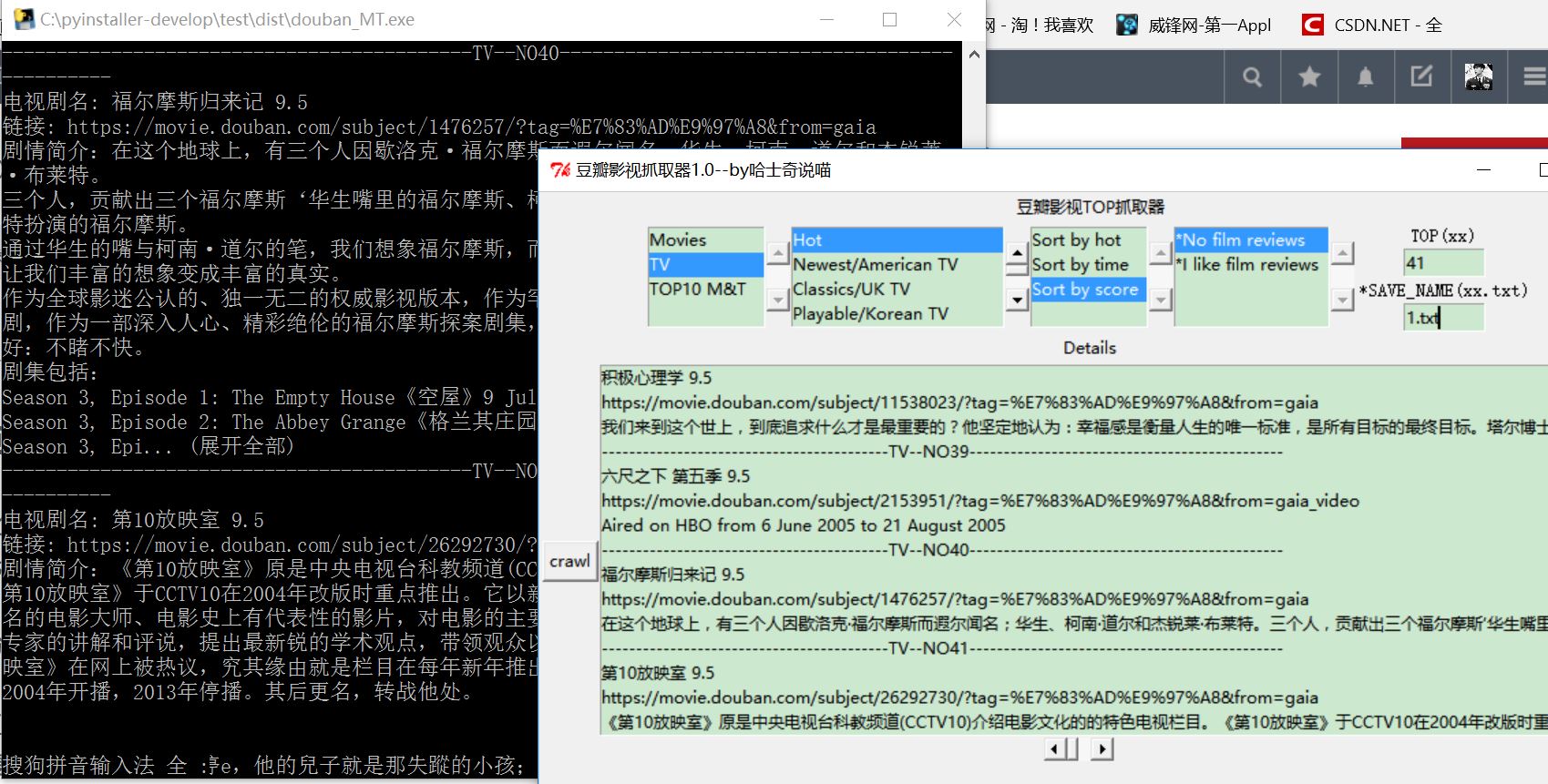
Python豆瓣爬虫(最简洁的豆瓣250爬虫,随机选择电影)
案例背景
电影才是世界艺术,所以我一直想看完豆瓣250,那么就重新拾起我的爬虫知识。
以前刚学爬虫那啥也不会,python语法都没弄清楚,现在不一样了,能用最为简洁的代码写出爬虫250的代码。 代码实现
导入包ÿ…

【知乎强大书单】在数据分析、挖掘方面,有哪些好书值得推荐?
入门读物: 深入浅出数据分析 (豆瓣) 这书挺简单的,基本的内容都涉及了,说得也比较清楚,最后谈到了R是大加分。难易程度:非常易。 啤酒与尿布 (豆瓣) 通过案例来说事情,而且是最经典的例子。难易程度&#…
Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶下)
Python 2.7 IDE Pycharm 5.0.3 Firefox 47.0.1 如有兴趣可以从如下几个开始看起,其中有我遇到的很多问题: 基础抓取(限于“豆瓣高分”选项电影及评论)请看Python自定义豆瓣电影种类,排行,点评的爬取与存…
Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶上)
Python 2.7 IDE Pycharm 5.0.3 Firefox 47.0.1
具体Selenium及PhantomJS请看PythonSeleniumPILTesseract真正自动识别验证码进行一键登录 一些自动化应用实例请看SeleniumPhantomJS自动续借图书馆书籍 至于GUI的入门使用请看Python基于Tkinter的二输入规则器(乞丐版) 比较…
![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://img-blog.csdnimg.cn/direct/a736d872c6fc410b9c31bb70c1d3f03b.png)
[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码
1.安装requests第三方库
在终端中输入以下代码(直接在cmd命令提示符中,不需要打开Python)
pip install requests -i https://pypi.douban.com/simple/
从豆瓣网提供的镜像网站下载requests第三方库
pip install requests
是从国外网站下…

爬虫(三)lxml+requests(豆瓣Top250电影)
回家之后就不想学习了…
这次用的是lxml库,因为听说比起BeautifulSoup它的速度更快,然后就想了解一下。(全部的代码在最下面)
import库
from lxml import etree
import requests
import json
# from time import sleep
这是要…